The Costs of Thread Synchronization
Written 2012-12-04
Tags:Monte-Carlo-Simulation Cache-Line-Sharing Atomic-Operations Caches
Recently I implemented a set of simple programs that use Monte-Carlo simulations to estimate the value of PI. I ran it on a few different machines to see the cost of different thread syncronization methods on these architectures.
The final approximation is the ratio of points in the circle to total points, and must be scaled by 4 to match a simulation of a full circle and square centered on (0,0). Since we can approximate the ratio of areas via the Monte-Carlo method, we solve for PI and approximate PI via the adjusted area ratios.
Genpfault pointed out I should play with numactl on this box to enforce splitting over sockets or locality to a single socket.
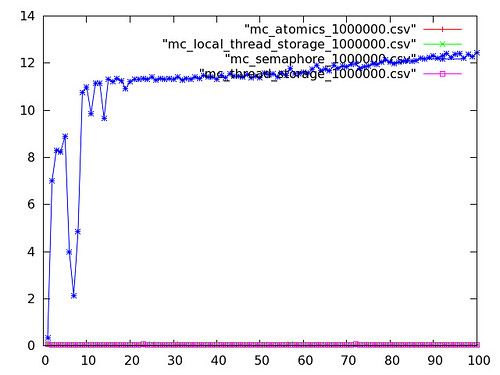
Next is the same data with the semaphore plot removed, as it made the scale awful.
Interestingly, once you discount outliers, atomic operations on this platform appear to be no more expensive than using independent threads. I suspect this is due to the fact that the N455 is really a single-core CPU - with only a single L1 cache, there won't be any cacheline-sharing.
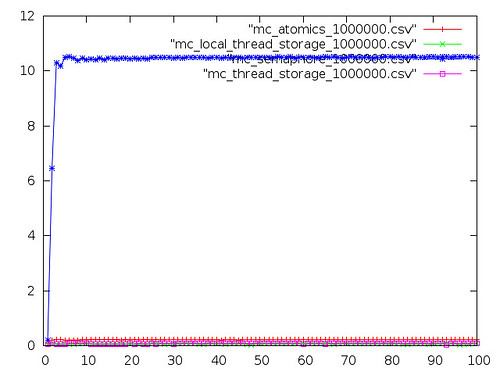
Here's the same plot but with semaphores removed and scale reset.
As expected, atomic operations are slower than independent threads on this platform, but similarly so to other multi-core devices. Atomics are still much faster than semaphores.
The Algorithm
This algorithm approximates the value of pi with a Monte-Carlo simulation. Effectively, this works by pseudo-randomly placing points in a domain, evaluating them, and tallying results. In our case, the domain is the set of x-y pairs from (0,0) to (1,1). The evaluation function checks if the distance from the point to (0,0) is greater than 1. The tallying consists of two counters - points farther than 1 away from (0.0), and points closer than 1 to (0,0).The final approximation is the ratio of points in the circle to total points, and must be scaled by 4 to match a simulation of a full circle and square centered on (0,0). Since we can approximate the ratio of areas via the Monte-Carlo method, we solve for PI and approximate PI via the adjusted area ratios.
The Synchronization Options
Binary Semaphore/Mutex
This is a standard mutex operation - only a single thread at a time can control it, and any thread who tries to reserve it when it is already reserved will block until it is available. These are fairly heavyweight structures that usually involve contacting the operating system for resolution when multiple threads want the mutex.Atomic Operations
Atomic operations have the ability to read/modify/write all in one instruction, or the ability to rollback an operation that failed to acheive atomicity, and report it to the user. In this way, two threads can share a single variable in memory, and each thread can modify it with atomic operations. However, this still doesn't scale to large numbers of threads due to cache-line sharing and coherency-tracking.Thread-based storage in a shared area
This mode allocates all thread-control structures and counters in a linear block of memory. Each thread has its own value to increment, but because they're near each other in memory, there may be some contention for cache-lines. Had I though about it earlier, I'd've placed all the counters in one linear block and the thread-control structures in another to try and illustrate the effect.Thread-based storage local to each thread
This mode uses a variable unique to each thread-function. This is nearly the same as above, but effectively places the variables in areas that will not be vulnerable to cache-line sharing.The Machines
Each plot shows execution time(Y) in seconds versus to the number of threads used(X). The number of computations is fixed at 1 Million, and the work is divided as evenly as possible between the threads. Additionally, each run was run a single time, so the graphs are somewhat noisy.
Intel CoreDuo-T2300 running Linux 3.2
The first box is my old CoreDuo powered ThinkPad T60 laptop. Semaphores are pretty unscalable. Atomics scale better, but are still surprisingly expensive. Thread-local options work much better, and with a good number of threads, it is possible to beat the single-threaded performance(untrue for atomics and semaphores).
Intel Core2Duo-T7600 running Linux 3.2
The next box is my current Core2Duo powered ThinkPad T60P laptop. The results are similar to the CoreDuo results, but the Core2Duo is quite a bit faster(as expected).
Intel dual Xeon 5650 running Linux 3.2
This box is my webserver and VM host. It has two six-core chips and hyperthreading, so it is expected that the runtime of scalable implementations of the benchmark will decrease in execution time up to or around using 24 threads. However, I couldn't take down the minecraft VMs that are also on this box, so I won't put as much faith in these numbers. Semaphores were quite slow and leveled off well before we reached 24 threads. Atomics scaled better here than on the above two intel chips, which I find suprising - I expected that if any threads ended up on the second chip, this would be much slower. However, accumulating the results local to each thread was the definite winner.Genpfault pointed out I should play with numactl on this box to enforce splitting over sockets or locality to a single socket.
Texas Instruments MicroSPARC running OpenBSD 5.1
The next graph is from my 50MHz MicroSPARC running OpenBSD. This one is interesting because it performs surprisingly well. However, since Compare-and-Swap was only implemented with SPARCv9, and MicroSPARC is a SPARCv8, there were no atomic operations to test. Additionally, since this is a single-core machine, flat curves are expected. Lastly, the performance for the semaphore mode isn't bad when using only one thread, so uncontended semaphores aren't too expensive on this box, but contended ones ( thread counts 2-100 ) are terrible.
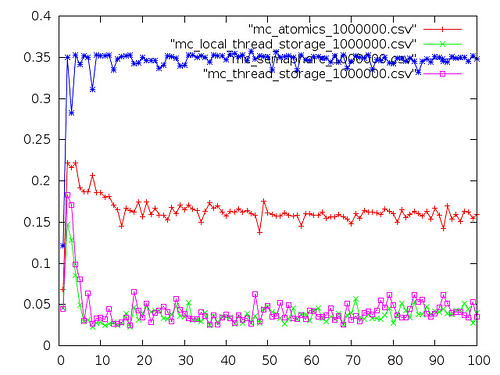
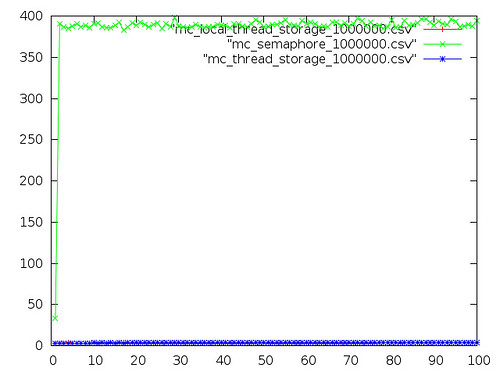
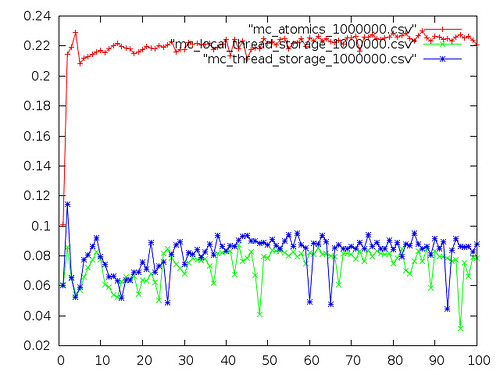
Intel Atom N455 running OpenBSD 5.2
This pair of graphs is from Ax0n'a single-core, hyperthreaded netbook running OpenBSD 5.2. The first graph should seem familiar - it seems OpenBSD semaphores are expensive. I'm not sure what the dip around 7 threads is; it probably warrants running the benchmark a few more times.
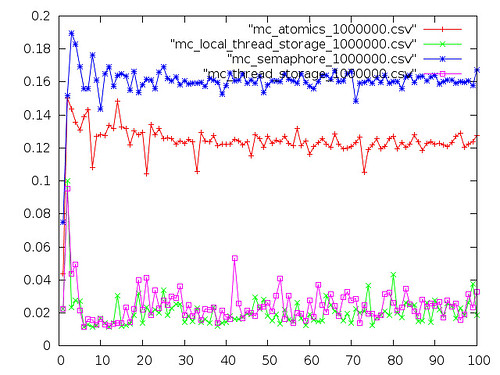
Next is the same data with the semaphore plot removed, as it made the scale awful.
Interestingly, once you discount outliers, atomic operations on this platform appear to be no more expensive than using independent threads. I suspect this is due to the fact that the N455 is really a single-core CPU - with only a single L1 cache, there won't be any cacheline-sharing.
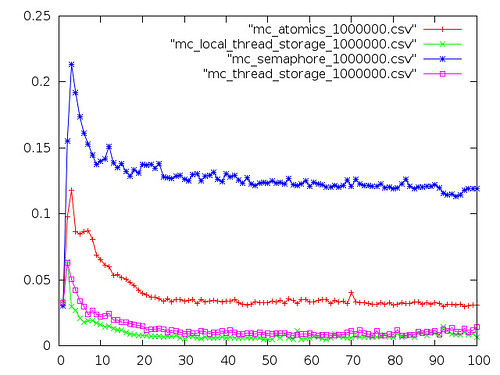
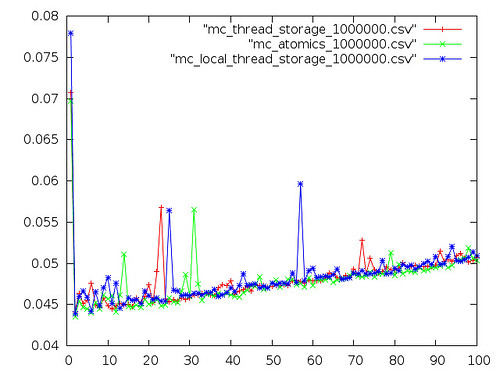
IBM PowerPC Quad-G5 running OSX 10.5
This pair of graphs is from CCCKC's Mac-Pro. Similar to OpenBSD, semaphore performance is slow and skews the scale so that you can't see anything else.
Here's the same plot but with semaphores removed and scale reset.
As expected, atomic operations are slower than independent threads on this platform, but similarly so to other multi-core devices. Atomics are still much faster than semaphores.
Conclusions
Atomic operations aren't a magic bullet
On the platforms that support them, atomic operations can be much better than semaphores. However, even less thread communication scales even better.Semaphore cost can vary widely over different platforms
At first I thought that OpenBSD/SPARC32 just had slow semaphores. However, after running the same benchmark on OSX/PPC-G5 and OpenBSD/Intel, it seems that Linux just has really cheap semaphores. Additionally, on all platforms, the semaphore benchmark ran best with only a single thread. Lastly, on every platform, the semaphore benchmark was the worst of the benchmarks.Often times, a single-thread can do pretty well
On CoreDuo and Core2Duo a single thread beat any number of threads using atomics or semaphores. On Xeon, a single thread was equivalent to all cores when using atomics, and was better than using semaphores.Costs of synchronization should be mitigatable
Costs should be mitigatable by doing more work between synchronization or communication with other threads. The work being done by this benchmark is quite simple. It consists of two calls to rand_r(), computing distance-squared, a comparison, and an action based on that comparison. As the complexity of the work done goes up, the ratio of the time spent synchronizing vs time spend working should go down quite a bit.Source Code
Source code is available at https://github.com/rsaxvc/monte-carlo-benchmark. Slight modifications were needed for OSX, whose atomic builtins are named differently than GCC's default ones, as well as OpenBSD, which needed changes for the path for bash.